| How a
Search Engine Works Pratik Naik |
|
|
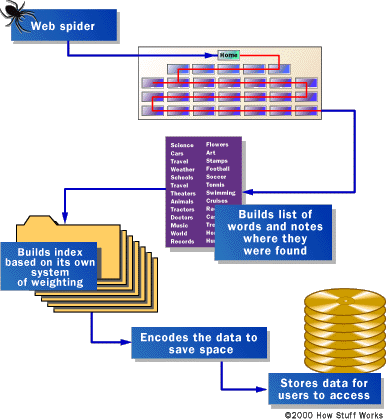
When first think about searching any thing on INTERNET first thing come to our mind is go to Google.com , Right? That is true because Google.com is very much popular Search Engine in the Whole Wide World of the internet. Search engine is the popular term for an information retrieval (IR) system. While researchers and developers take a broader view of IR systems, consumers think of them more in terms of what they want the systems to do namely search the Web, or an intranet, or a database. Actually consumer would really prefer a finding engine, rather than a search engine. An Itsy-Bitsy Beginning Before a search engine can tell you where a file or document is, it must be found. To find information on the hundreds of millions of Web pages that exist, a search engine employs special software robots, called spiders, to build lists of the words found on Web sites. When a spider is building its lists, the process is called Web crawling. (There are some disadvantages to calling part of the Internet the World Wide Web -- a large set of arachnid-centric names for tools is one of them.) In order to build and maintain a useful list of words, a search engine's spiders have to look at a lot of pages. How
does any spider start its travels over the Web? The usual
starting points are lists of heavily used servers and very
popular pages. The spider will begin with a popular site,
indexing the words on its pages and following every link found
within the site. In this way, the spidering system quickly
begins to travel, spreading out across the most widely used
portions of the Web.
"Spiders" take a Web page's content and create key search words that enable online users to find pages they're looking for. Google.com began as an academic search engine. In the paper that describes how the system was built, Sergey Brin and Lawrence Page give an example of how quickly their spiders can work. They built their initial system to use multiple spiders, usually three at one time. Each spider could keep about 300 connections to Web pages open at a time. At its peak performance, using four spiders, their system could crawl over 100 pages per second, generating around 600 kilobytes of data each second. Keeping everything running quickly meant building a system to feed necessary information to the spiders. The early Google system had a server dedicated to providing URLs to the spiders. Rather than depending on an Internet service provider for the domain name server (DNS) that translates a server's name into an address, Google had its own DNS, in order to keep delays to a minimum.
Search engines match queries against an index that they create. The index consists of the words in each document, plus pointers to their locations within the documents. This is called an inverted file. A search engine or IR system comprises four essential modules: While users focus on "search," the search and matching function is only one of the four modules. Each of these four modules may cause the expected or unexpected results that consumers get when they use a search engine. |
|