| Mining
Retail E-Commerce: Lessons from path breaking Case Studie Omprakash Chandrakar |
 |
|||
|
Introduction
The
advent of e-commerce revolutionized every industry. Every
aspect of commerce, from sales pitch to final delivery, could
be automated and made available 24 hours a day, all over the
world. B2B solutions carried this one step further, allowing
vertical partnerships and co-branding. Businesses found a new
incentive to bring their data into the digital age. And
dynamic content allowed the first truly personalized,
interactive websites to come into being, all through the magic
of e-commerce. Meanwhile,
away from the digital storefront, data warehouses were
springing up in the machine rooms of industry - gargantuan
information repositories for the collection of every bit of
business trivia. The sources of data were of the old realm of
business: point-of-sale terminals, inventory databases,
transaction records. Attempts to understand the data, first
with statistical tools, later with OLAP systems, met with
limited success - until the introduction of Data Mining. Using
machine learning algorithms, Data Mining software finds hidden
patterns in the data, and uses them to form new rules and
predict the future behavior of customers - turning that
mountain of data into valuable knowledge and untapped business
opportunities. Using a website as a data collection tool is now commonplace, because of its interactivness, simplicity, and unobtrusiveness. So naturally one would want to analyze this data with the best data mining techniques available. The results of the data mining - the rules which say which customers are likely to buy what products at the same time, or who is about to switch to your competitor - would ideally then be integrated into your dynamic website - thus providing an automated, end-to-end, targeted marketing and e-CRM tool. The paper is organized as follows. Section 1 preface to data mining and retail e-commerce. In section 2 we navigate through a robust e-commerce and data mining architecture. Section 3 describes lessons from path breaking case studies. We conclude with a summary in section 4. Section
1: Data Mining and Retail E-Commerce
So, why is e-commerce
different? In short, many of the hurdles are significantly
lower. As compared to ancient or shielded legacy systems, data
collection can be controlled to a larger extent. We now have
the opportunity to design systems that collect data for the
purposes of data mining, rather than having to struggle with
translating and mining data collected for other purposes. Data
are collected electronically, rather than manually, so less
noise is introduced from manual processing. E-commerce data
are rich, containing information on prior purchase activity
and detailed demographic data. In addition, some data that
previously were very difficult to collect now are accessible
easily. For example, e-commerce systems can record the actions
of customers in the virtual store, including what they
look at, what they put into their shopping cart and do not
buy, and so on. Previously, in order to obtain such data
companies had to trail customers (in person), surreptitiously
recording their activities, or had to undertake complicated
analyses of in-store videos. It was not cost-effective to
collect such data in bulk, and correlating them with
individual customers is practically impossible. For e-commerce
systems massive Amounts of data can be collected
inexpensively. Unlike many data mining
applications, the vehicle for capitalizing on the results of
miningthe systemalready is automated. Also, because the
mined models will fit well with the existing system, computing
return on investment can be much easier. The lowering of several
significant hurdles to the applicability of data mining will
allow many more companies to implement intelligent systems for
e-commerce. However, there is an even more compelling reason
why it will succeed. As implied above, the volume of data
collected by systems for e-commerce dwarfs prior collections
of commerce data. Manual analysis will be impossible, and even
traditional semi-automated analyses will become unwieldy. Data
mining soon will become essential for understanding customers. The
lessons described in this paper are based on case studies and
extensive contemporary literature study. While the lessons can
be drawn, both at business implementation and technical
fronts, here, in this paper we attempt to summarize our
inferences on the business front.
Section
2 Integrating E-Commerce and Data Mining: Architecture In
this section we give a high level overview of architecture for
an e-commerce system with integrated data mining. In this
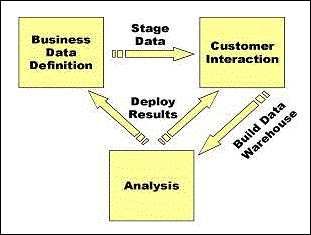
architecture there are three main components, Business Data
Definition, Customer Interaction, and Analysis. Connecting
these components are three data transfer bridges, Stage Data,
Build Data Warehouse, and Deploy Results. The relationship
between the components and the data transfer bridges is
illustrated in Figure 1.
In
the Business
Data Definition component the e-commerce business user defines
the data and metadata associated with their business. This
data includes merchandising information (e.g., products,
assortments, and price lists), content information (e.g., web
page templates, articles, images, and multimedia) and business
rules (e.g., personalized content rules, promotion rules, and
rules for cross-sells and up-sells). From a data mining
perspective the key to the Business Data Definition component
is the ability to define a rich set of attributes (metadata)
for any type of data. The
Customer Interaction component provides the interface between
customers and the e-commerce business. This interaction
could take place through a web site (e.g., a marketing site or
a web store), customer service (via telephony or email),
wireless application, or even a bricks-and-mortar point of
sale system. For effective analysis of all of these data
sources, a data collector needs to be an integrated part of
the Customer Interaction component. To provide maximum
utility, the data collector should not only log sale
transactions, but it should also log other types of customer
interactions, such as web page views for a web site. The
Analysis component provides an integrated environment for
decision support utilizing data transformations, reporting,
data mining algorithms, visualization, and OLAP tools. The
richness of the available metadata gives the Analysis
component significant advantages over horizontal decision
support tools, in both power and ease-of-use. The
Stage Data bridge connects the Business Data Definition
component to the Customer Interaction component. This
bridge transfers (or stages) the data and metadata into
the Customer Interaction component. Having a staging
process has several advantages, including the ability to test
changes before having them implemented in production, allowing
for changes in the data formats and replication between the
two components for efficiency, and enabling e-commerce
businesses to have zero down-time. The
Build Data Warehouse bridge links the Customer Interaction
component with the Analysis component. This bridge transfers
the data collected within the Customer Interaction component
to the Analysis component and builds a data warehouse for
analysis purposes. The Build Data Warehouse bridge also
transfers all of the business data defined within the Business
Data Definition component (which was transferred to the Customer
Interaction component using the Stage Data bridge).
The
last bridge, Deploy Results, is the key to closing the
loop and making analytical results actionable. It
provides the ability to transfer models, scores, results and
new attributes constructed using data transformations back
into the Business Data Definition and Customer Interaction
components for use in business rules for personalization.
Section
3 Lessons from path breaking Case Studies The goal of designing any
data mining application should be to make it easy for an
organization to utilize business intelligence capabilities,
including reporting, visualizations, etc. There
are now many commercial and freeware software packages that
provide basic statistics about web sites, including number of
page views, hits, traffic patterns by day-of-week or
hour-of-day, etc. These
tools help ensure the correct operation of web sites (e.g.,
they may identify page not found errors) and can aid in
identifying basic trends, such as traffic growth over time, or
patterns such as differences between weekday and weekend
traffic. With
growing pressure to make e-commerce sites more profitable,
however, additional analyses are usually requested.
These analyses are usually deeper, involving discovery
of factors, and more strategic to the business. After
analyzing various retail e-commerce sites, we propose some
analyses that would be useful in practice. In each of the
following subsections we describe the lessons learned from
path breaking case studies. Case
1: Bot Analysis Web
robots, spiders, crawlers, and aggregators, which we
collectively call bots, are automated programs that create
traffic to websites. Bots
include search engines, such as Google, web monitoring
software, such as Keynote and Gomez, and shopping comparison
agents, such as mySimon. Because such bots crawl sites and may
bring in additional human traffic through referrals, it is not
a good idea for websites to block them from accessing the
site. In addition to these good bots, there are e-mail
harvesters, which try to look for e-mails that are sold as
e-mail lists, offline browsers (e.g., Internet Explorer has
such an option), and many experimental bots by students and
companies trying out new ideas. Here
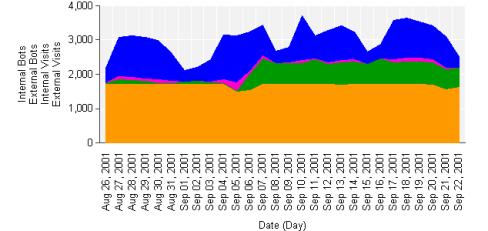
are the data obtained from some case studies: Percentage
of sessions generated by bots is 23%
at MEC (outdoor gear) 40%
at Debenhams
Figure
2: Bot Analysis Observations: 1.
Bots account for 5 to 40% of sessions. Due to the
volume and type of traffic that they generate, bots can
dramatically skew site statistics. 2.
Even when the human traffic is fluctuating
substantially, the bot traffic still remains the same. 3.
After registering with search engine the external bot
traffic increases substantially, as expected. Lesson: 1.
Accurately identifying bots and eliminating them before
performing any type of analysis on the website is critical. 2.
Just because the traffic is increasing immediately
after registering with search engines, one should not get
overwhelmed, because substantial part of that might be bot
traffic. 3.
Many commercial web analytic packages include basic bot
detection through a list of known bots, identified by their
user agent or IP. However,
such lists must be updated regularly to keep track of new
evolving and mutating bots. Case
2: Session Timeout Analysis
Enhancing
the user browsing experience is an important goal for website
developers. One hindrance to a smooth browsing experience is
the occurrence of a session timeout. A user session is
determined by the application logic to have timed out (ended)
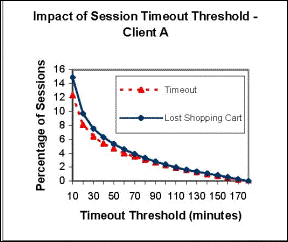
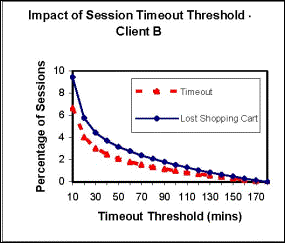
after a certain predefined period of inactivity. Figure
2 shows the impact of different session timeout thresholds set
at 10-minute intervals on two large clients
Observations: 1.
If the session timeout threshold were set to 25 minutes
then for client A, 7% of all sessions would experience timeout
and 8.25% of sessions with active shopping carts would lose
their carts as a result. However, for client B, the numbers
are 3.5% and 5% respectively. 2.
Several user sessions were experiencing a timeout as a
result of a low timeout threshold and lost their active
shopping cart Lesson: 1.
The software save the shopping cart automatically at
timeout and restore it when the visitor returns. 2.
Clients must determine the timeout threshold only after
careful analysis of their own data. 3.
Setting the session timeout threshold too high would
mean that fewer users would experience timeout thereby
improving the user experience. 4.
A larger number of sessions would have to be kept
active (in memory) at the website thereby resulting in a
higher load on the website system resources. 5.
Setting an appropriate session timeout threshold
involves a trade-off between website memory utilization (which
may impact performance) and user experience. So maintain a
right balance. Case
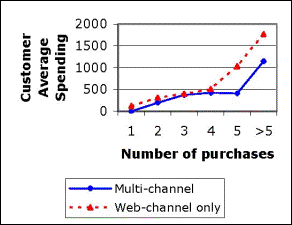
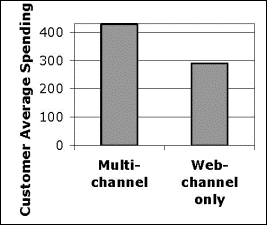
3: Simpsons paradox On a few occasions it
becomes difficult to present insights that are seemingly
counter-intuitive. For instance, when analyzing a clients
data we came across an example of Simpsons paradox
(Simpson, 1951). Simpsons paradox occurs when the
correlation between two variables is reversed when a third
variable is controlled.
Figure 3: Average yearly
spending per customer for multi-channel and web-only
purchasers by number of purchases (left), and average yearly
spending per customer for multi-channel and web-only
purchasers (right). We were comparing
customers with at least two purchases and looking at their
channel preferences, i.e., where they made purchases.
Do people who shop from the web only spend more on
average as compared to people who shop from more than one
channel, such as the web and physical retail stores? Observations:
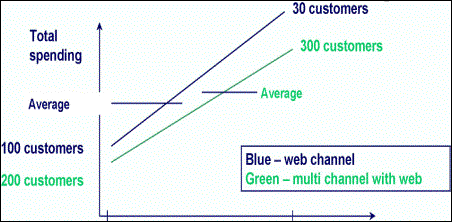
1.
Explain
counter-intuitive insights - The reversal of the trend in the
above case is happening because a weighted average is being
computed and the number of customers who shopped more than
five times on the web is much smaller than the number of
customers who shopped more than five times across multiple
channels. Such
insights must be explained to business users.
Figure
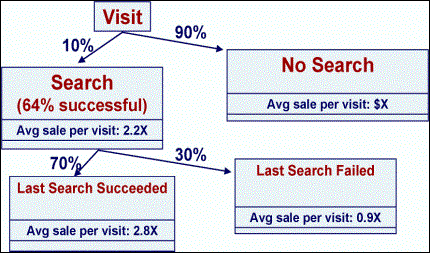
4: Clarification of Simpsons paradox Case 4: Search
Effectiveness
Analysis Significant time and effort is spent in designing forms that are aesthetically pleasing. The eventual use of the collected form data for the purpose of data mining must also be kept in mind when designing forms. Figure 4 shows the effectiveness of search.
Figure
5: Effectiveness of search. Observation:
Lesson:
Case
5: Data Auditing
Data cleansing is a
crucial prerequisite to any form of data analysis. Even when
most of the data are collected electronically, as in the case
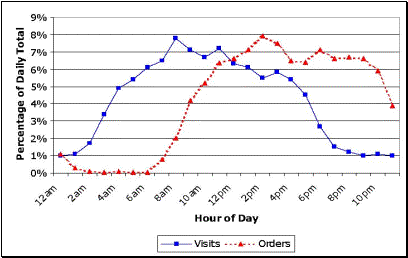
of e-commerce, there can be serious data quality issues. Consider
following graph that shows distribution of visits and orders
by hour-of-day for a real website.
Observation: 1.
The above
graph shows an interesting pattern in visit and order. Orders
follow visits by five hours, while we are expecting visits and
orders to be close to each other in time. Lesson: 1.
Data cleansing is a crucial prerequisite to any form of
data analysis. 2.
Weve found serious data quality issues in data
warehouses that should contain clean data, especially when the
data were collected from multiple channels, archaic
point-of-sale systems, and old mainframes. As shown in Figure
6 that orders seem to follow visits by five hours.
It turned out different servers were being used to log
clickstream (visits) and transactions (orders), and these
servers system clocks were off by five hours. One was set
to GMT and the other to EST.
Section 4: Summary
We reviewed the integrated
architecture of Data Mining with E-Commerce, which provides
powerful capabilities to collect additional clickstream data
not usually available in web logs, while also obviating the
need to solve problems usually bottlenecking analysis (and
which are much less accurate when done as an afterthought),
such as sessionization and conflating data from multiple
sources. We
believe that such architectures where clickstreams are logged
by the application server layer are significantly superior and
have proven themselves with various E-commerce
sites. Our focus on Business to
Consumer (B2C) e-commerce for retailers allowed us to drill
deeper into business needs to develop the required expertise
and design out-of-the-box reports and analyses in this domain.
Further, we believe that most lessons will generalize to other
domains outside of retail e-commerce. The top 3 lessons are: 1.
Accurately identifying bots and eliminating them before
performing any type of analysis on the website is critical. 2.
Setting an appropriate session timeout threshold
involves a trade-off between website memory utilization (which
may impact performance) and user experience. So maintain a
right balance. 3.
Counter-intuitive
insights must be explained to business users in depth. E-commerce is still in its
infancy, with less than a decade of experience.
Best practices and important lessons are being learned
every day. The
Science of Shopping is well developed for bricks and mortar
stores.
|
||||